Deep-tech AI research · Australia
Speech learned from physics — not datasets.
From random starts to stable vowel targets using a single adaptive controller.
ah 100% · ee 100% · oo 93%
From random initial states (research-stage)
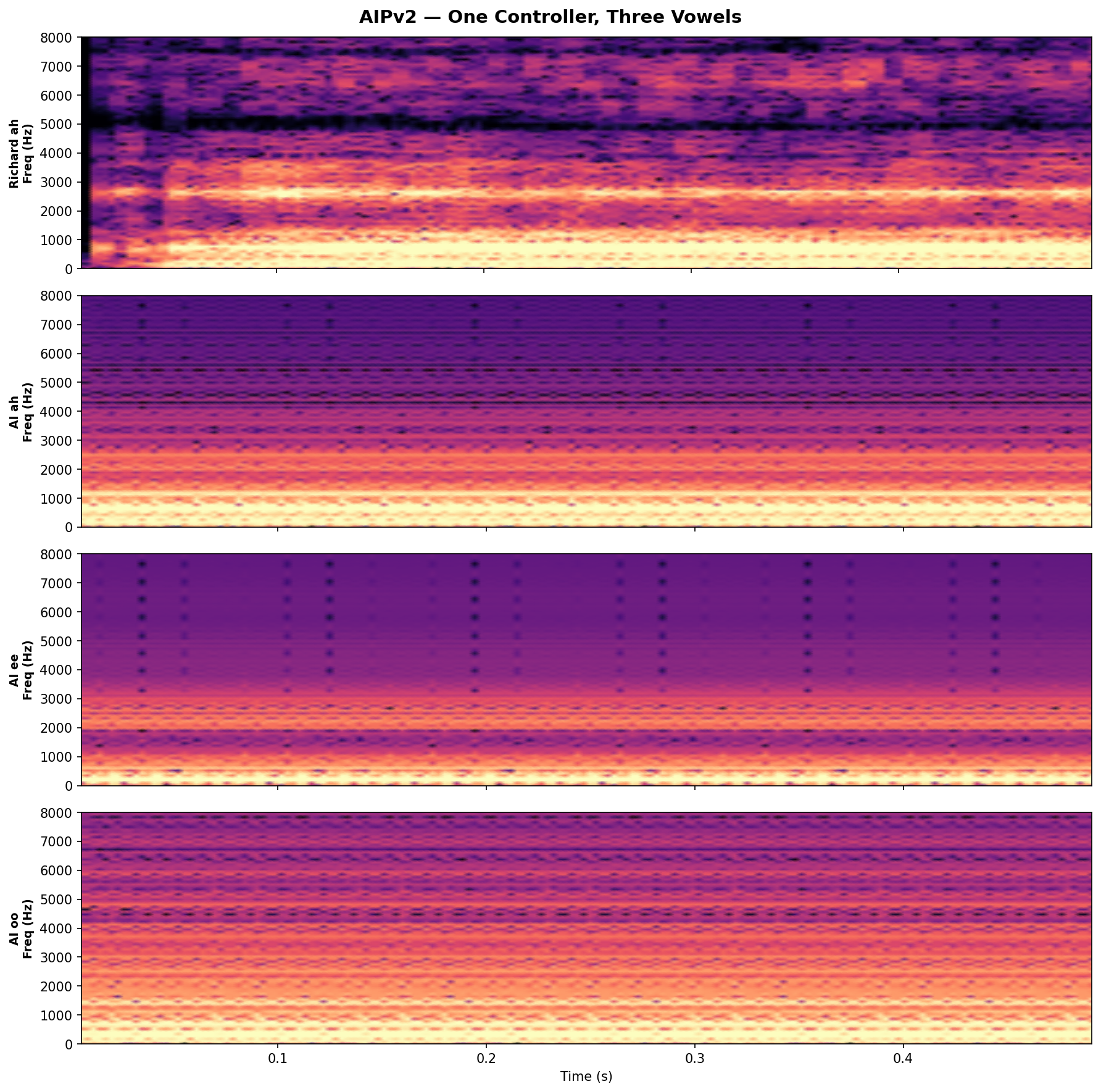
What you’re seeing
From random initial conditions to a controlled acoustic outcome
Observed behaviour on our instrument—not an internal method diagram.
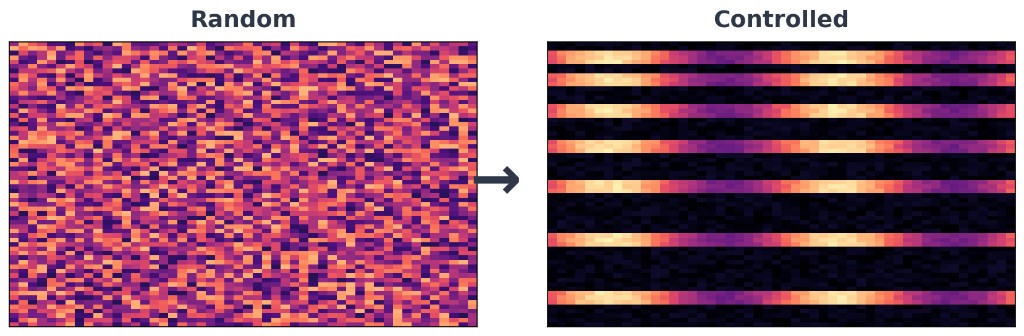
Observed behaviour, not internal method.
What we proved
- ·Convergence from random initial states
- ·One controller, multiple vowel targets
- ·No recorded speech datasets
- ·Stable acoustic targets with closed-loop control
Representative gated scores
ah 100% · ee 100% · oo 93%
Full definitions and protocol under diligence.
What you’re seeing
Vowel evidence (F1 / F2)
A minimal, high-signal view of target structure in the acoustic space we care about—without exposing implementation details.
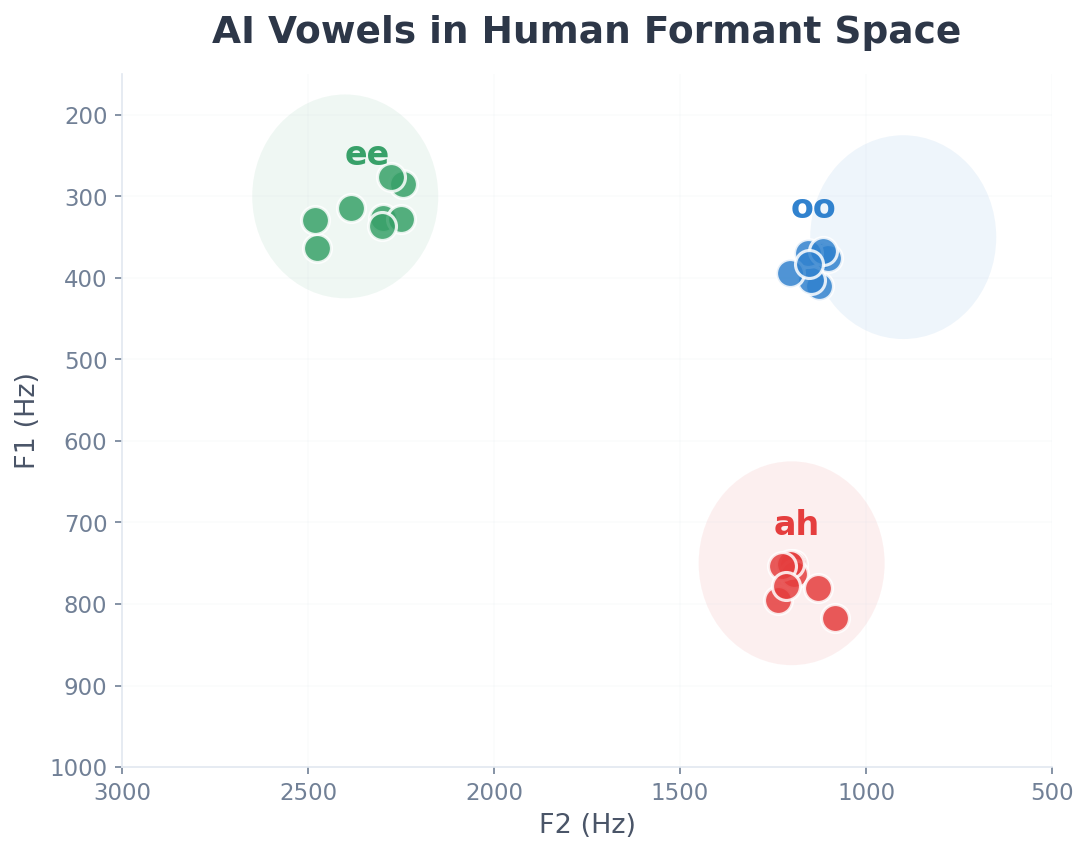
Observed behaviour, not internal method.
What you’re seeing
Convergence from a random start
Representative run: formant error (Hz) versus step—lower is better.
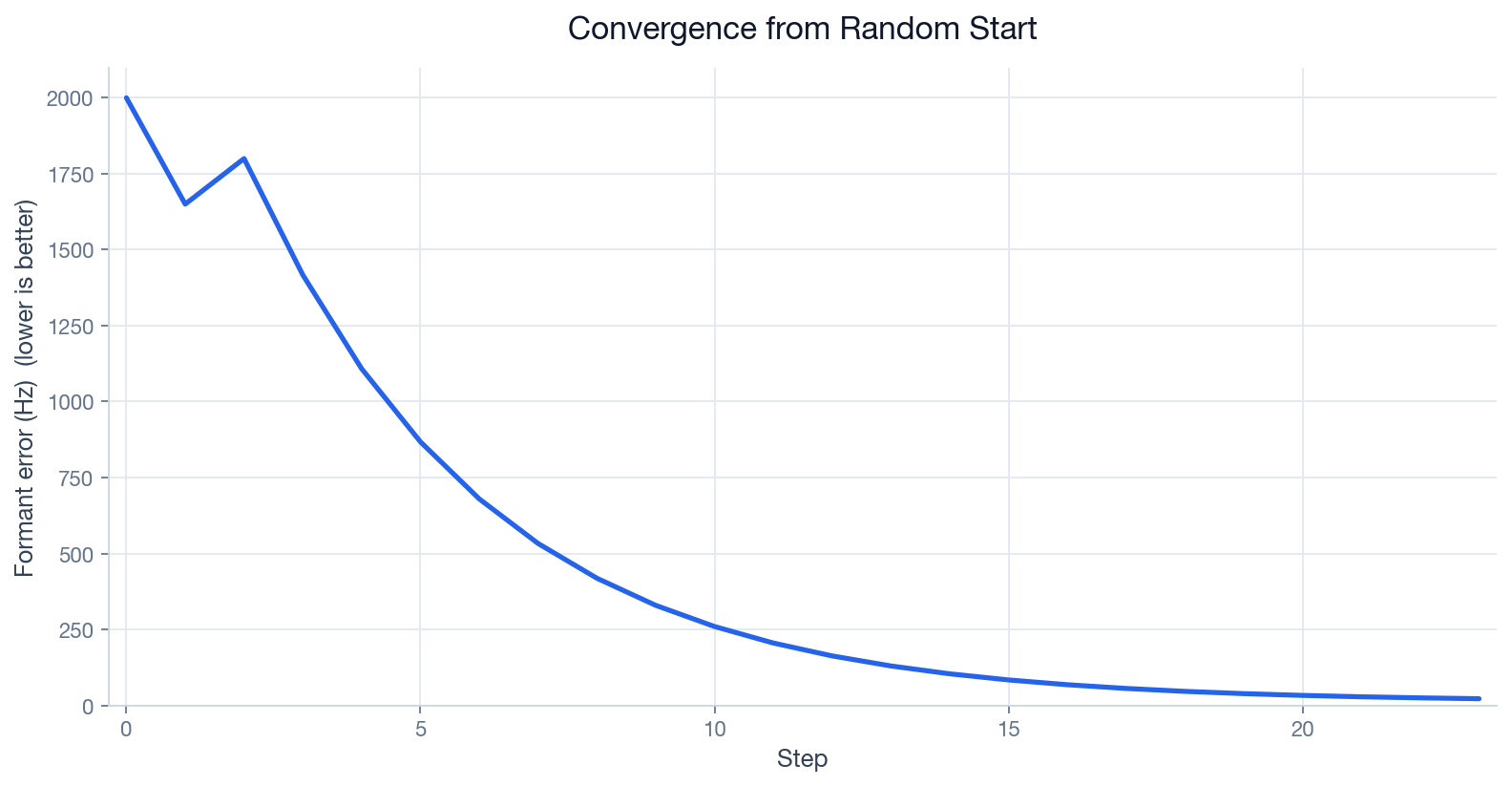
Observed behaviour, not internal method.
What you’re seeing
Repeatability across runs
A compact snapshot of consistency across recent internal runs.
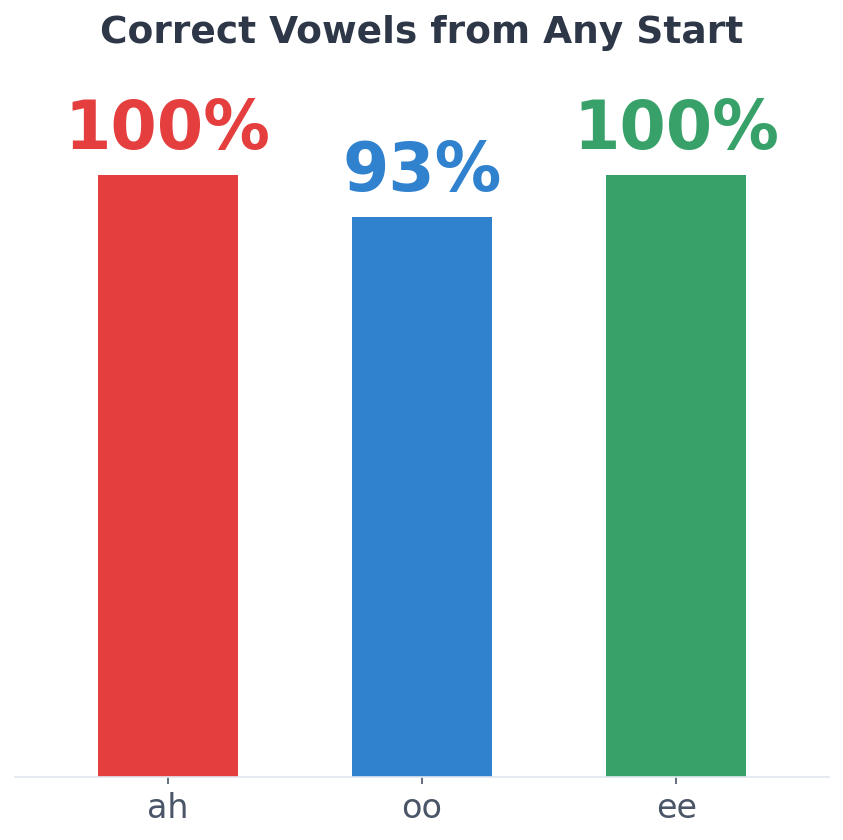
Observed behaviour, not internal method.
Why this matters (without the recipe)
The visuals above are the public bar: controlled, repeatable speech production from random initial states, learned without recorded speech datasets. Method detail stays diligence-gated.
Research progress
High-level milestones. Detailed methods and evaluation design are shared under appropriate agreements—we publish the story, not the recipe.
Phase 1 — Discovery at scale
Early 2026
Large-scale search over a parametric vocal instrument, with only high-level acoustic feedback. Multiple independent seeds converged on structured, voice-like output—strong evidence that the landscape rewards real production physics, not a single lucky path.
Evolution of sound (representative run)
Random exploration sharpening into structured, voice-like output over many generations.
Recurrent discovered gesture
A short acoustic onset pattern that appeared across runs—a signature of convergent discovery rather than manual design.
Top composed sample (high objective score)
Primitives combined into one of the strongest-scoring utterances from the discovery phase.
Search found compelling acoustic structure, but the next chapter required memory, generalisation, and controllable targets. Phase 2 is that chapter.
Phase 2 — Adaptive motor control
2026 — active
coarse → refine → stable
A single adaptive controller steers the instrument toward different targets. Vowels and transitions are learned outcomes under the same closed-loop principle as Phase 1. Qualitative audio in Evidence is labelled for provenance—it is not assumed to match every newer internal run.
Recent internal milestone
Recent runs show reliable convergence toward target vowel structures from random initial states, using a single adaptive controller. Behaviour is fully closed-loop: coarse motor convergence, then finer acoustic stabilisation, with distinct vowel targets—including acoustically narrow basins—without dependence on recorded speech datasets for these outcomes.
Figures for this milestone appear near the top of this page; older clips in Evidence may not match the newest runs.
Distinct steady vowels demonstrated
Unified controller across targets
Real-time synthesis & sensing
Multi-phoneme learning
Training on a single sound allows the system to settle on fixed motor patterns. Training across multiple sounds forces it to use feedback and produce different outputs for different targets.
Recent experiments include multi-sound vocal sequences and transitions (for example “ah” → “ee”) using a shared controller—still foundational motor-acoustic research, not conversational speech or text-to-speech.
A single controller learns multiple distinct sounds and transitions, rather than memorising separate trajectories; the headline behaviour story is summarised in the visuals above.
This marks the shift from isolated sound discovery toward controllable, repeatable motor-acoustic production under closed-loop feedback—without publishing the internal training interface here.
Acoustic evidence
These audio clips predate the latest closed-loop milestone narrative.
Read the Research progress section for the current behaviour-level story.
Qualitative clips and spectrograms—useful for listening; quantitative claims are in the figures above.
Representative outputs from an earlier adaptive-controller phase. The latest behaviour-level visuals live near the top of this page.
Steady vowels
Same controller, different targets—each a learned production, not a separate baked-in model.
“ah”
“ee”
“oo”
Between vowels
Continuous motion between targets—evidence of control, not hard cuts.
For the latest behaviour-level summary—including repeatable convergence from random starts—see Research progress above.
“ah” → “ee”
“ah” → “oo”
Spectral validation
Human reference (top) versus learned vowels—distinct formant structure per vowel. Same qualitative demo phase as the clips above.
The audio examples above predate the latest closed-loop milestone narrative; use them as listening context alongside the figures at the top of the page.
A different path to speech
Every current speech system depends on recorded human data to function. We are exploring what happens when that dependency is removed entirely.
The current generation of systems is hitting structural limits around data, control, and interpretability.
If speech can be learned without data, the entire speech stack changes.
The voice AI market is dominated by systems trained to reproduce patterns in enormous speech corpora. That path works for products—but it bundles dataset risk, opacity, and a ceiling on how “understanding” is grounded.
Incumbent trajectory
- · Scale data, scale parameters, scale compute
- · Quality tied to licensing and coverage of voices
- · Harder to prove what the model “knows” about production
Our thesis
- · Ground learning in a real-time acoustic instrument and closed-loop feedback
- · Let structure emerge under tight scientific constraints—not by hand-authoring the answer
- · Build a moat around methodology and measurable progression, not a one-off demo
Positioning
Post-dataset speech systems
No text-in → waveform-out product narrative. This is foundational motor-acoustic research.
Evidence
Reproducible runs
Independent experiments converged on speech-like behaviour—then we moved to adaptive control.
Today
Multi-sound & transitions
Recent internal work emphasises repeatable convergence and stable holds on distinct vowels—including demanding targets.
Tomorrow
Richer inventory
Expanding the sound set, robustness, and real-world interfaces—still without giving up the core thesis.
The question we started with
Infants do not download a corpus. They explore, listen, and calibrate. We asked whether an artificial learner could follow a similarly grounded path: act → perceive → improve—with scientific discipline and without shortcutting the problem with a scripted phoneme machine.
Emergence, not theatre
If the system cannot discover a behaviour through the allowed learning interface, we treat that as a research result—not something to patch over with hand-tuned production rules.
Coaching, not puppetry
External evaluation shapes the objective landscape; it does not micromanage the motor solution. That separation is central to what we’re proving.
Physics-first audio
Sound is produced by a deterministic acoustic engine running in real time—so claims about “what the AI did” stay tied to measurable waveforms.
Interpretability by design
Motor controls map to production levers you can reason about—an advantage for science, safety storytelling, and long-term product paths.
How the loop works (conceptual)
No teacher ever provides the correct motor trajectory.
We stay intentionally high-level here. Implementation, loss design, and training contracts are part of our research package—not a webpage.
Act
The learner proposes motor commands; the instrument turns them into audio in real time.
Sense
A causal perception stack summarises what was actually produced—no peeking at the future waveform.
Align
External evaluation scores progress toward targets while preserving the integrity of the motor path.
Compound
Skills stack: new sounds build on stabilised behaviours rather than resetting the system.
What we protect
The defensibility is in the integration: instrument design, perception, curriculum, and evaluation—tuned as one system.
Real-time acoustic core
Low-latency, deterministic synthesis so experiments are repeatable and claims stay falsifiable.
Closed-loop learning discipline
Training assumes the instrument is in the loop—mirroring how real vocal systems operate.
Rigorous evaluation
Human-in-the-loop listening, spectral checks, and automated gates—so “it sounds right” isn’t a vibe.
Cloud-scale experimentation
Phase 1 validated at serious compute breadth; Phase 2 pairs local iteration with elastic cloud for campaigns.
For investors & partners
Acoustic Intelligence is an Australian deep-tech research company pursuing a category-defining thesis—one that does not depend on access to proprietary speech datasets: voice as a learned motor skill on a controllable physical instrument, not only as a statistical mirror of scraped audio.
- ·Timing: Regulators and enterprises are asking harder questions about data provenance, voice rights, and interpretability—our stack is aligned with that shift.
- ·Traction shape: Convergent discovery at scale, then adaptive control with multi-sound sequences and transitions; public clips are labelled by provenance, while the latest internal milestone emphasises repeatable convergence from random starts and distinct vowel targets under closed-loop feedback (see Progress).
- ·What we’re raising toward: Expanding the learned inventory, hardening robustness, and selective partnerships—without diluting the scientific bar.
- ·What you get in diligence: Methodology walkthroughs and metrics under NDA—not a public playbook.
AWS
Large discovery campaigns run on cloud compute; adaptive training mixes efficient local iteration with scalable runs. We participate in programs that support serious infrastructure for deep research teams.
About
Founded by Richard James. Based in Brisbane, Australia.
Acoustic Intelligence exists to push a principled boundary: machines that earn speech through interaction with physics—measured honestly, improved iteratively, and positioned for the next decade of voice technology.
This site showcases outcomes and direction. It is not an instruction manual.
Contact
Investment conversations, strategic partnerships, and qualified research collaboration—we reply to serious inbound.
richard@acousticintelligence.ai