Speech AI today is built by compressing human recordings.
We are building systems that learn how to speak.
If this approach works, it replaces how speech systems are built.
We have demonstrated repeatable vowel production from random initial states using a single learned controller on a physical voice system.
The limitation of current systems
Modern speech systems depend on massive datasets of recorded human audio. Their capabilities are constrained by what has been collected, licensed, and statistically reproduced.
This creates structural limits: dependence on proprietary data, weak interpretability, and limited grounding in how speech is actually produced.
A different approach
We train neural controllers to produce speech by interacting with a physical acoustic system in real time.
No datasets. No imitation. No predefined articulation paths.
Speech is treated as controlled motor-acoustic production: converging from variability into stable targets, then holding them—still learned through interaction with physics, not by compressing a corpus.
Evidence of progress
- · Convergent discovery of structured acoustic behaviour across independent runs
- · Transition from large-scale search to adaptive motor control
- · Demonstrated multi-vowel production from a shared controller
- · Recent internal milestone: repeatable convergence toward target vowel structures from random initial states, with coarse-to-fine stabilisation and distinct vowel targets (including acoustically narrow basins)
- · Multi-sound learning with a single controller without collapsing to a shared average behaviour
- · Real-time synthesis grounded in physical constraints
Public-safe snapshot (same asset family as the homepage):
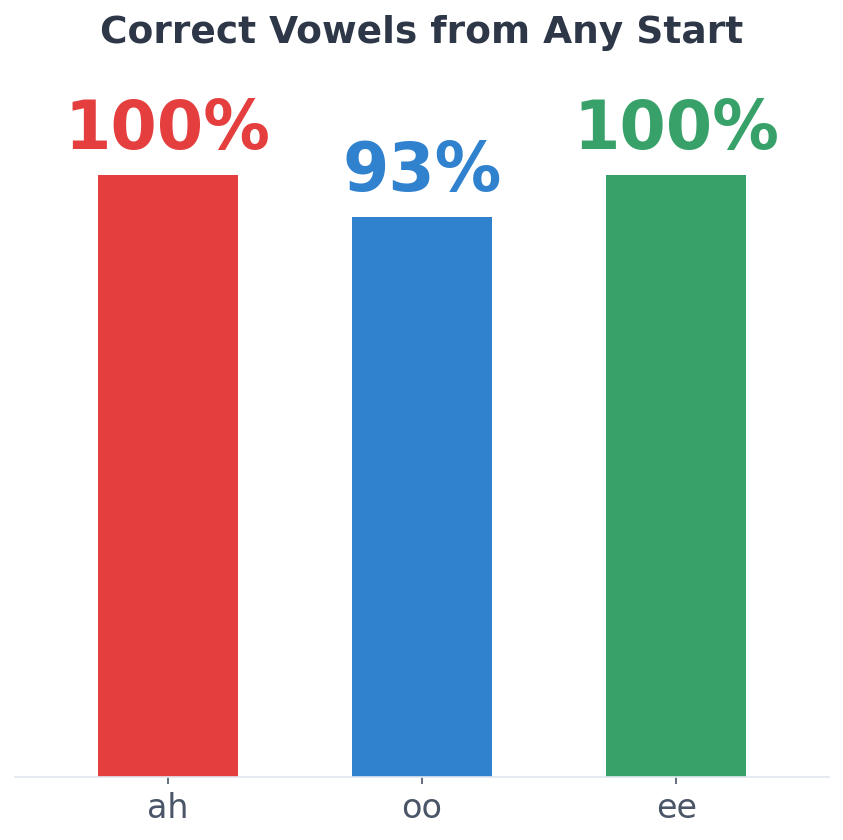
Observed behaviour summary—not internal optimisation tooling. Full figure set: homepage visuals.
Outcomes vary across seeds and evaluation choices; headline claims here are behaviour-level summaries pending broader validation and partner review.
The system learns multiple phonemes with no architectural changes—different articulations emerge from the same shared controller using only scalar feedback.
Method details are intentionally withheld on the public site; diligence covers evaluation design under NDA.
Why now
- · Increasing regulatory pressure around data provenance
- · Rising cost and scarcity of high-quality speech datasets
- · Demand for interpretable and controllable AI systems
- · Availability of compute to explore new training paradigms
What this unlocks
If speech can be learned without datasets, the entire speech stack changes.
Initial applications centre on environments where dataset dependence creates legal, operational, or strategic constraints.
- · Systems independent of proprietary voice data
- · Controllable speech generation (motor-grounded)
- · Stronger interpretability and safety narratives
- · New foundations for voice, robotics, and embodied AI
Trajectory
We are expanding from controlled vowel production toward richer sound inventories, robustness, and real-world interfaces—without compromising the core principle of learning through interaction with physics. The near-term story is repeatability and control, not a broader “speech product” launch.
Acoustic Intelligence is an Australian deep-tech company building a new paradigm for speech systems.
Contact for investor discussions